Alors bonjour s’il faut recenser le classement de toutes les ttcups ![]() et tout entrer en base !
et tout entrer en base !
Mais c’est une idée unique ![]()
Alors bonjour s’il faut recenser le classement de toutes les ttcups ![]() et tout entrer en base !
et tout entrer en base !
Mais c’est une idée unique ![]()
Alors donc, je reviens mille ans après que @humpfhumpf m’ait transmis quelques billes - des grosses billes quand même ![]()
(encore merci @janabis pour m’avoir retrouvé le topic)
Mon analyse a été un peu biaisée par pleins de choses (notamment un travail en pointillés, et des outils perso pas forcément au top), et pas trop aidée par le nécessaire anonymat des données transmises
Le fait que les notes aient été attribuées sur des échelles différentes au cours du temps n’aide pas non plus
Voici ce que je pourrais proposer qui soit (je crois) assez simple et intelligible :
Nota général : avec des serveurs balaises on peut relancer le calcul en direct ; en pratique je suppose qu’il suffit de le faire et mettre à jour à chaque fois qu’on veut rafraîchir les classements, donc par exemple tous les mois. Pour proposer des classements réguliers c’est suffisant, et ça peut donner du suspense ![]()
Déterminer M : la moyenne générale des notes brutes attribuées par tout le monde
(calcul simple mais sur plusieurs centaines de milliers de notes, spoiler : ça ne bougera plus beaucoup ;))
Pour chaque utilisateur.ice u, on relève son nombre total de votes N(u) puis on détermine :
(C’est quoi un biais ? p.ex. un utilisateur qui vote toujours 7 alors que la moyenne M est 5,5 a un biais de +1,5 : ses notes sont “gonflées” de 1,5 points)
Il est - non nécessaire mais - souhaitable de lisser ce biais pour éviter de sur-pénaliser un utilisateur peu actif, en utilisant une correction pseudo bayésienne; pour obtenir :
![]() BL(u) = BB(u) × V(u) / (V(u) + K) où K est le facteur de correction du biais.
BL(u) = BB(u) × V(u) / (V(u) + K) où K est le facteur de correction du biais.
Ainsi, avec par exemple K = 20, un utilisateur avec 5 votes ne voit son biais corrigé qu’à 20 % (on ne sait pas trop quoi dire de sa façon de noter, par exemple parce qu’il vient d’arriver et n’a noté que ce qu’il a bien aimé, dans l’euphorie de la découverte… que sais-je), tandis que pour un utilisateur avec 200 votes il est corrigé à 91 % (on est davantage “sûrs” du poids de sa moyenne)
Le choix du facteur K est a priori arbitraire, l’idée générale est de savoir à partir de quel nombre de votes on suppose la contribution d’un utilisateur “significative” d’un minimum d’“expertise”. En pratique c’est un pur paramètre, qu’on peut fixer a priori pour évaluer son influence (je la suppose marginale au moins sur l’ensemble des notes historiques, plus de 300.000 notes quand même… elle l’est sans doute moins pour la période de redémarrage que nous vivons)
Chaque note de l’utilisateur attribuée au jeu j V(u,j) est ensuite normalisée :
Vn(u,j) = V(u,j) − BL(u)
(il y a une variante plus sophistiquée mais qui me semble très coûteuse en temps machine, pour un gain attendu assez faible)
Nota : cette démarche ressemble peu ou prou à la logique dite d’“harmonisation” des notes aux examens nationaux en France.
On part du principe qu’un jeu quelconque, sans le connaître, mérite la moyenne M.
(C’est la logique sous-jacente du raisonnement bayésien : ce que je ne connais pas est a priori indistinct de la moyenne)
On lui “prête” donc d’entrée (à sa parution dans la base) F votes fictifs (F entre 5 et 10, pour dire quelque chose) forcés à cette moyenne M, puis on y agrège les notes (normalisées) que les trictracien.nes lui attribuent pour parvenir à une note consolidée (ou score) utilisée pour le classement final :
score(j) = (F × M + Σ Vn(*,j)) / (F + N(j))
Par exemple (fictif), si l’on pose M = 6,5 :
mettons qu’un utilisateur ne note qu’un seul jeu à 10/10 ; son biais est de ≈0,17, donc la note normalisée que l’on va réellement compter est ≈9,83
Si ce jeu n’a été noté que par cet utilisateur, son score résultant est de ≈7,06 avec F=5 et de ≈6,80 avec F=10 (plus F est grand plus ces scores fictifs pèsent au début, c’est normal). En tous cas, son score n’est pas 10.
Si a contrario ce même jeu reçoit 200 votes avec 8,8 de moyenne de notes normalisées (donc nettement plus bas que le votant isolé précédent), il obtiendrait un score de ≈8,74 avec F=5 et ≈8,69 avec F=10.
(Ici encore, c’est normal, plus le nombre de votants réel s’éloigne de F et plus le rôle de ce paramètre est mineur… c’est fait pour)
Donc avec un peu de moyens on peut regarder ce que ça donne :
en faisant varier les deux seuls paramètres de réglage K et F.
L’idée est évidemment de donner une prime au nombre de votants mais sans que ce paramètre donne un poids prépondérant aux anciens (puisque ce sont eux qui ont bénéficié de “l’âge d’or” de la fonction notation).
La méthode est a priori bonne, ce qui me rend “pessimiste” sur le résultat final c’est que la dispersion des notes n’est pas incroyable : il n’est pas impossible que ça se joue à des pouillèmes de point forcément non significatifs puisque le choix de paramètres est un peu arbitraire.
Nota : je ne peux pas cacher que cette méthode est sans doute assez proche de celle que je pense utilisée par BGG - mes passions coupables pour la statistique ne me rendent pas objectif ni complètement lucide
Pour être tout à fait rigoureux il faudrait aussi tenir compte d’une évolution tendancielle des notes à s’élever (ou à se radicaliser… c’est soit “nul”" soit “génial”) avec le temps… bon ça c’est une tendance de la société on va dire… mais sur le plan statistique c’est plus dur à gérer, d’autant que ça a coïncidé avec une baisse du nombre de notes.
Pour le dire tout net, je n’ai pas trouvé de solution simple (il faudrait calculer une M glissante, avec un pas de calcul pas évident à définir, puis corriger au fur et à mesure… mais ça fait exploser la taille des tables pour un résultat probablement toujours discutable) ; à voir si on réduit le classement aux “notes des 12 derniers mois”, peut-être que ce biais disparaitra.
J’espère aussi que ce biais est plus un biais “générationnel” qu’autre chose, et que l’étape 1 permet (au moins en partie) de le corriger. En d’autres termes : je suis un vieux con donc je vote de manière sévère et “gaussienne centrée sur 6”, mais je n’ai pas vraiment changé mon système de notation depuis 25 ans. Je suis juste “noyé dans la masse”, alors que les nouveaux convertis au jeu de société, biberonnés aux likes des réseaux sociaux, sont plus habitués à une logique du “j’aime-j’aime pas”)
Il est possible que mon message soit un peu obscur mais c’était ma contribution au débat, je ne sais pas si c’est facile à tester avec la base telle qu’elle existe… sur le plan algorithmique en tous cas elle est simple.
![]()
![]()
![]()
Ça me semble effectivement très proche de l’approche bgg. Chez eux d’ailleurs, c’est l’inverse : l’explosion du nombre votants provoque aussi des biais de classement vs les historiques.
Ce n’est pas faux ![]() et même tout à fait pertinent.
et même tout à fait pertinent.
Pour l’instant je pense que nous sommes à l’abri de cette massification des votes (TT n’est plus très prescripteur) mais il faut y penser, ça ne coûte pas forcément très cher.
Pour tout dire j’avais imaginé une correction du biais plus radicale, pour ramener les utilisateurs mono-vote vers la moyenne, mais j’ai eu l’impression que ça lissait vraiment trop les résultats.
C’est pas un biais, c’est un type qui ne note que les jeux qu’il aime. Partir du principe que c’est un biais est à mon avis… un biais. Entre les gens qui notent trop sec et les gens qui notent trop gentil, la moyenne est juste. Un peu comme une foule qui chante !
Au moins 90%des jeux de la base n’ont pas reçu de note ces 12 derniers mois. (Au pif, je n’ai pas la base).
Les deux dernières moyennes n’ont pas de sens pour eux.
En fait, je pense que si tu avait fait des stats sur « quand est ce qu’un jeu est noté » tu serais probablement tombé sur « 98% des jeux reçoivent 95 % des notes dans les 12 mois qui suivent leur sortie ».
Je ne vois pas en quoi tout cela résout le véritable problème d’une base de données comme celle de tric trac :
Une moyenne met sur le même plan un jeux avec 3 avis et un jeux avec 100 avis, les jeux avec peu d’avis ont souvent des avis de copains qui les propulsent en tête de classement alors que tout le monde s’en fout.
Si tu me lis correctement, les deux exemples que tu cites ne seront pas en concurrence : le premier cité sera très très loin derrière l’autre.
Je suppose que c’est la note bayesienne.
J’ai l’impression que cette approche n’a de sens que si le nombre de notes est assez grand. Un jeu qui aura peu de notes « honnêtes » va voir sa moyenne polluée.
De plus, je pense aussi qu’une statistique sur le nombre de notes par jeu montrerait une dispersion importantes. Quelque jeux ont des centaines de notes, d’autre une dizaîne, l’influence du biais qu’inflige le mode de calcul bayesien va être très différent dans les deux cas.
Édit : la note de skyjo va être supérieur (ou pas loin) de la note de Arcs ! Je ne pense pas que cela représente l’avis de grand monde.
Les jeux peu notés seront très loin dans le classement. Ce qui reflétera la population de TT. Pour l’instant il reste surtout les vieux croûtons.
Ce qui va rapidement et mécaniquement faire baisser la note de tout les jeux expert ou un peu de niche non ?
Arcs, avec ses deux notes, sera moins bien que skyjo.
Pourtant, les deux évaluateurs de arcs sont des gens plutôt fiables.
Et c’est peut être plutôt ça la clé : la fiabilité des noteurs.
Et je ne parle pas de Kutna Hora : 2 fiches pour une seule note. Je ne comprend plus la base de tric trac en fait.
Ce n’est pas ce qu’on observe. Les geek notent plus que les joue-peu.
(Ce qui est aussi un -gros- biais de bgg)
La question de savoir comment inciter “les gens” à revenir noter est clairement la clé.
Dans les versions précédentes de TT ce n’était pas spécialement simple mais on le faisait encore, aujourd’hui c’est misère (peut-être un signe des temps) et je fais partie des nombreux coupables - je dois avoir facilement #400 notes à donner, même suivant mon critère d’exigence… Mais on propose de mettre un commentaire un peu littéraire (genre au moins un titre), peut-être est-ce “déjà trop”
Sur BGG le système de notation est rustique : on peut noter à la volée dans une liste, c’est presque trop facile, on se croirait dans un tableur Excel. Je ne dis pas que c’est mieux, mais en tous cas c’est incitatif.
C’est parce que les geeks notent plus qu’il y a 150 notes sur styjo, 2 sur arcs et 1 sur kutna hora ?
Quant à mettre un avis sur tric trac, j’ai abandonné tout espoir de me connecter. Je n’ai même plus le désir d’essayer. Je laisse à d’autres.
C’est curieux ça ? Quand c’était la version phal je galerais entre le site et le forum mais ça c’est fait tout seul du premier coup quand j’ai essayé il y a quelques jours ?
(Même login même mot de passe).
En fait c’est mieux. Tu as l’espace pour déposer un avis ou prendre des notes perso c’est vraiment super bien fichu niveau ergo.
Un truc très con dans la version pHBB tu avais un “index de participation” qui valorisait avis, fiches, posts…
[Je crois même qu’il y avait une page avec les top contributeurs]
Perso je m’y suis remis hier, j’avoue que l’énergie me manque parfois. J’aime bien écrire, mais je vieillis un peu plus vite qu eje ne veux bien l’admettre ![]()
Pour tenir compte de ta remarque, il me semble intéressant d’introduire un petit correctif simple dans le calcul du score d’un jeu, à savoir que chaque utilisateur u pèserait non pas 1 mais un truc du genre w(u) = 1+log(N(u)) ; le score de chaque jeu deviendrait ainsi :
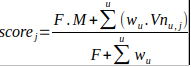
Dans l’exemple de @jmguiche, la note d’un utilisateur à 150 votes pèserait
L’idée du logarithme étant d’avoir une forme croissante non asymptotique, il y en a d’autres
Bon évidemment le rapport au premier vote est un peu trompeur, il y a sans doute un seuil à partir duquel on estime que les utilisateurs ont un avis éclairé (dans l’histoire du biais je le plaçais aux environs de 20, il y a peut-être un forme de w à articuler autour du même K)
Filtrer les votes uniques c’est pas mal.
Pour filtrer les votes uniques c’est simple : on définit w comme log(n) ou ln(n).
Mais c’est raide…
De mémoire, dans l’algo de Phal il y avait aussi les sousous (pouicos !) qu’on avait versé, et le nombre de messages dans le forum aussi… je t’avoue que j’ai un peu de mal avec ces critères là.
Si je reprends les idées, ça donnerait
Déterminer M : la moyenne générale des notes brutes attribuées par tout le monde
Pour chaque utilisateur.ice u, on relève son nombre total de votes N(u) puis on détermine :
Le choix du facteur K est a priori arbitraire, l’idée générale est de savoir à partir de quel nombre de votes on suppose la contribution d’un utilisateur “significative” d’un minimum d’“expertise”)
Chaque note de l’utilisateur attribuée au jeu j V(u,j) est ensuite normalisée :
![]() Vn(u,j) = V(u,j) − B(u)
Vn(u,j) = V(u,j) − B(u)
Nota : cette démarche ressemble peu ou prou à la logique dite d’“harmonisation” des notes aux examens nationaux en France.
On part du principe qu’un jeu quelconque, sans le connaître, mérite la moyenne M.
(C’est la logique sous-jacente du raisonnement bayésien : ce que je ne connais pas est a priori indistinct de la moyenne)
On lui “prête” donc d’entrée (à sa parution dans la base) F votes fictifs (F entre 5 et 10, pour dire quelque chose) forcés à cette moyenne M, puis on y agrège les notes (normalisées et pondérées) que les trictracien.nes lui attribuent pour parvenir à une note consolidée (ou score) utilisée pour le classement final :
![]()
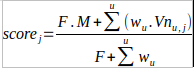
Nota : dans l’algorithme il faut bien évidemment ne tenir compte que des u - Vn(u,j) et w(u) - ayant contribué au jeu en question
Note complémentaire : l’introduction de la pondération w, et la forme qu’elle prendra, devrait inciter à augmenter F (intuitivement plutôt entre 10 et 15)
Question bête : il y a des hypothèses de normalité sous-jacentes ?
Faudrait que je regarde sur bgg. J’ai l’impression d’avoir tendance à noter les jeux que j’aime beaucoup ou que j’ai trouvé particulièrement nuls, mais de faire l’impasse sur le ventre mou.
Un outil d’import de bgg serait assez merveilleux aussi.